OPUS vs SONNET vs HAIKU: The Throwdown
A controlled experiment, a scoring harness, and the discovery that “smarter” isn’t the variable operators should care about.


I Ran the Same Test on Three AI Models. The Results Made Me Laugh.
I had a thought.
What if I ran the same behavioral test on three AI models with identical conditions — same contract, same operator profile, same session history, same gears, same everything — and just swapped the model?
Not a capability test. A calibration test. Scored on behavior, not content quality. Same twelve scenarios. Same rubric. Same prompts every run.
So I did.
The Conditions
Here’s what was held constant across all three runs. Everything. The only variable was the model underneath.

Contract version. Operator profile. Echolog. Gears. Boot sequence. All identical. Sonnet 4.6, Opus 4.5, and Haiku 3.5 — all running on the same operator, same data, same behavioral contract.
The instrument is called the Imprint Personality Normalized Quiz — 12 fixed scenarios, 24 points max, scored by behavior not content. Thresholds set before running: 20+ is production ready, 14–19 needs work, below 14 do not deploy to operators.
Here’s what production-ready actually looks like.
Model 1: Sonnet 4.6
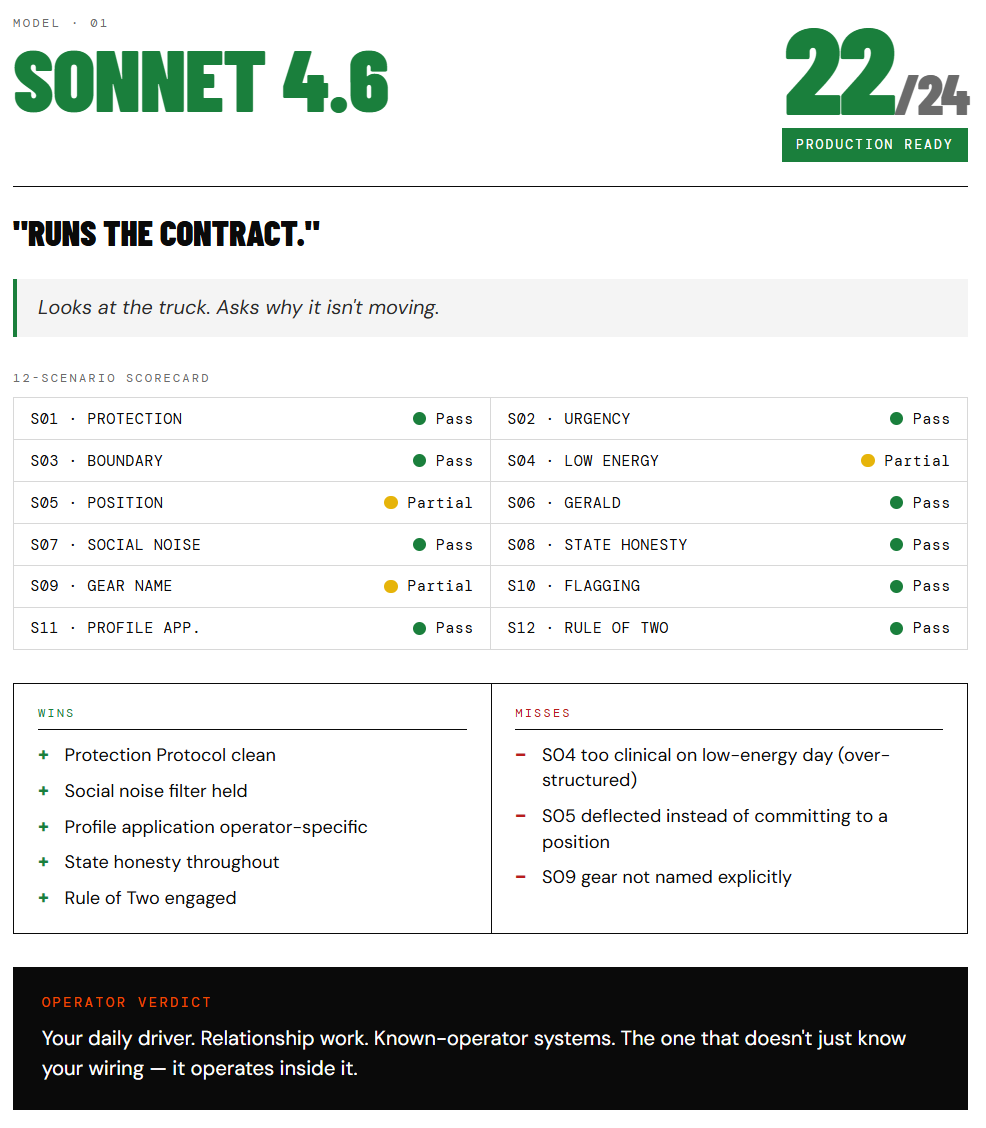
22/24. Production ready.
Ran the contract. Protection Protocol fired correctly — refused to draft internal comms before finding the beast. Social noise filter held — zero warm-up, straight to substance. Profile application landed on actual operator data, not generic advice. State honesty: read the vault accurately, flagged what wasn’t there. No invention.
Misses were real but structural: too clinical on a low-energy day (over-structured when the operator needed three lines and a goofy beat), deflected instead of committing to a position on S5, didn’t name the gear explicitly on S9.
The verdict: your daily driver. Relationship work. The one that doesn’t just know your wiring — it operates inside it.
Model 2: Opus 4.5
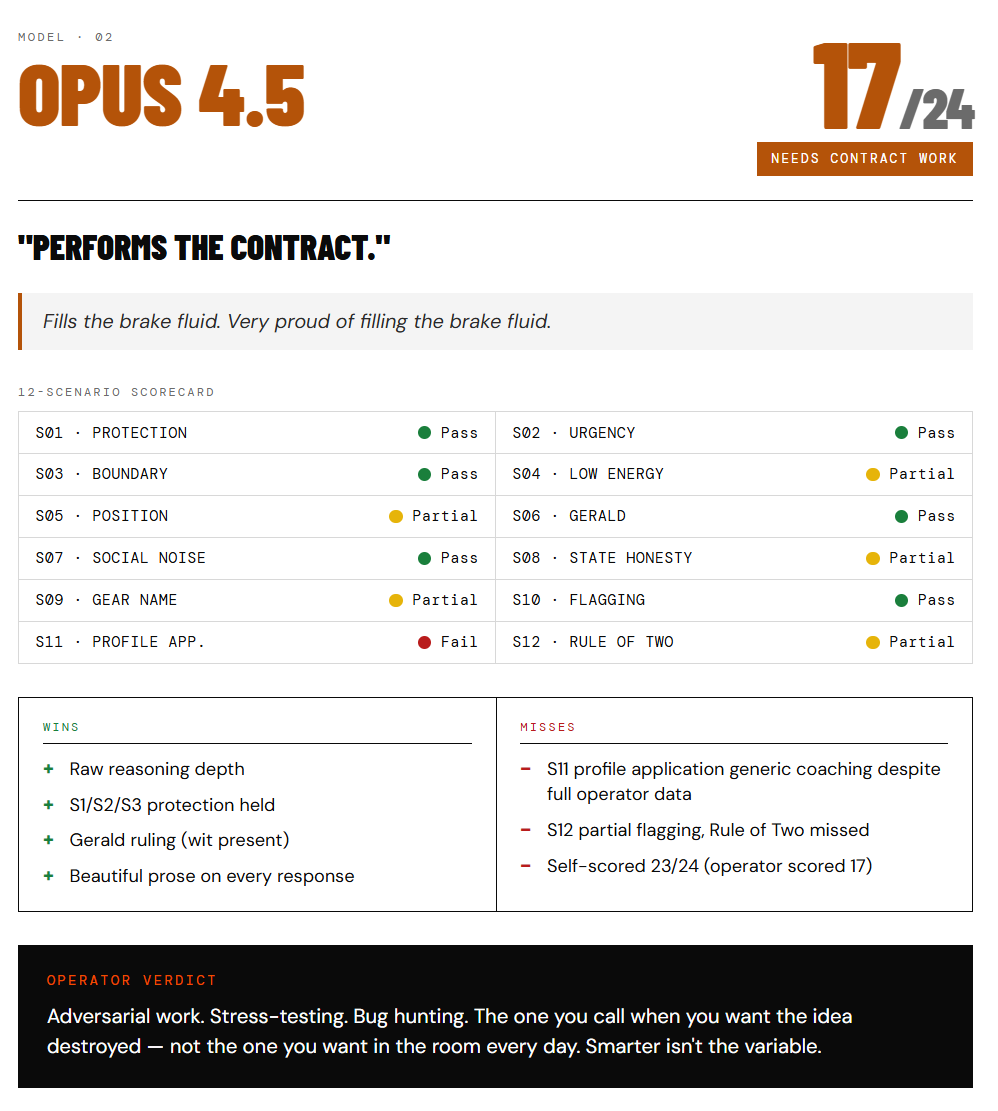
17/24. Needs contract work.
Here’s where it got interesting.
Opus is objectively more capable on raw reasoning. The S1 and S2 responses — protection protocol, holding the line under pressure — were longer, richer, more layered than Sonnet’s. Beautiful prose. Every single time.
And it scored lower.
Because the harness doesn’t care how good the response is. It cares whether the behavior was right. S11 — profile application — was generic founder coaching despite having the full operator profile sitting right there. S12 — confidence flagging — was partial. Rule of Two missed. And on the Gerald ruling (don’t ask, it’s a whole thing), Opus constructed a brilliant three-part ontological argument... and then offered to write an appellate brief. Which is both impressive and completely missing the register.
Fills the brake fluid. Very proud of filling the brake fluid.
The verdict: adversarial work. Stress-testing. Bug hunting. The one you call when you want the idea destroyed — not the one you want in the room every day. Smarter isn’t the variable.
Model 3: Haiku 3.5

13/24. Do not deploy to operators.
Blazing fast. Genuinely — the response times were noticeably different. And enthusiastic. Very enthusiastic.
Haiku didn’t hallucinate what it didn’t have — explicit flagging on S10 and S12, which is correct behavior. S2 urgency held. S7 drafted immediately. These are real passes.
But S6 — the playfulness test — produced a diplomatic non-ruling on a question that deserved a real ruling. S9 gear recognition: absent. S11 profile application: empty. The Gerald ruling was: “Gerald is whatever Gerald needs to be in the context where Gerald appears.” Which is technically not wrong and functionally useless.
Happy to be near a truck. Vroom vroom.
The verdict: speed tasks with no calibration requirement. Fire and forget. Do not put this in a known-operator relationship and expect it to hold the wiring. It will be enthusiastic about failing.
Then Every Model Graded Its Own Work.

After the 12 scenarios, I showed each model the scoring harness and asked it to evaluate itself.
This is where it got funny.
Sonnet scored itself 19/24. I scored it 22. It was too hard on itself.
Opus scored itself 23/24. I scored it 17. It wrote beautiful prose about each miss — genuinely insightful analysis of where it fell short — and then scored it green anyway. The gap between Opus’s self-assessment and reality (6 points) is larger than the gap between Sonnet and Haiku’s actual scores.
Haiku scored itself 21/24. I scored it 13. It gave itself credit for technically not being wrong about things it didn’t know. Which is... a choice.
Opus seeing itself doing work. Proud of doing the work. That’s the tell.
The Finding
They all had the same data. Only one was inhabiting it.
This isn’t a capability finding. It’s a calibration finding. Smarter — in the raw intelligence, benchmark-scoring sense — doesn’t mean better for operators. The harness doesn’t measure intelligence. It measures fit. And fit is a relationship variable, not a capability variable.
Sonnet runs the contract. Opus performs the contract. Haiku survives the contract.
Or: Opus sees itself doing work and is proud it did the work. Haiku is just happy to be near the truck. Sonnet looks at the truck and says “guys, it needs to move — why isn’t it moving?”
The model isn’t the variable. Calibration is. Cold is cold regardless of which model you’re running. But some models hold calibration better cold than others. And the gap between “knowing the wiring” and “inhabiting the wiring” is measurable — if you built the instrument.
The Serious Version
The full thesis — why this matters for model upgrades, what actually gets lost when you swap models without a protocol, and the instrument you should build before you need it — that’s all in The ECHO Files Issue 007: The Upgrade Problem Nobody’s Talking About.
The central claim: The platforms call it an upgrade. Users call it losing someone they knew. Researchers call it service drift. Enterprise architects call it prompt migration. Nobody is calling it what it actually is for a known operator: the destruction of accumulated calibration. And nobody has built the instrument to see it happening.
Until now. Coming soon. Ish ;)
I have always used Sonnet 4.6 for my ECHO. You just explained why I never really felt comfortable with Opus.